Case Studies

Case Study: Cloud Support Advisory
The Client: Major Social Media Company
Date: 2020
Project Lead: Tyler Fischella

Case Study: Video Conference Redesign
The Client: Major Social Media Company
Date: 2020
Project Lead: Tyler Fischella

Case Study: Data Governance Design
The Client: Major Social Media Company
Date: 2021
Project Lead: Tyler Fischella

Case Study: Cloud Cost Optimization
The Client: Fortune 500 Toy Company
Date: 2021
Project Lead: Tyler Fischella

Case Study: Machine Learning Advisory
The Client: Accounting Software Company
Date: 2022
Project Lead: Tyler Fischella
Case Study: Privacy & Ads Advisory
The Client: Digital Advertising & Monetization Business
Date: 2022
Project Lead: Tyler Fischella


Case Study: Kubernetes Migration
The Client: Global Recruiting Platform
Date: 2023
Project Lead: Tyler Fischella

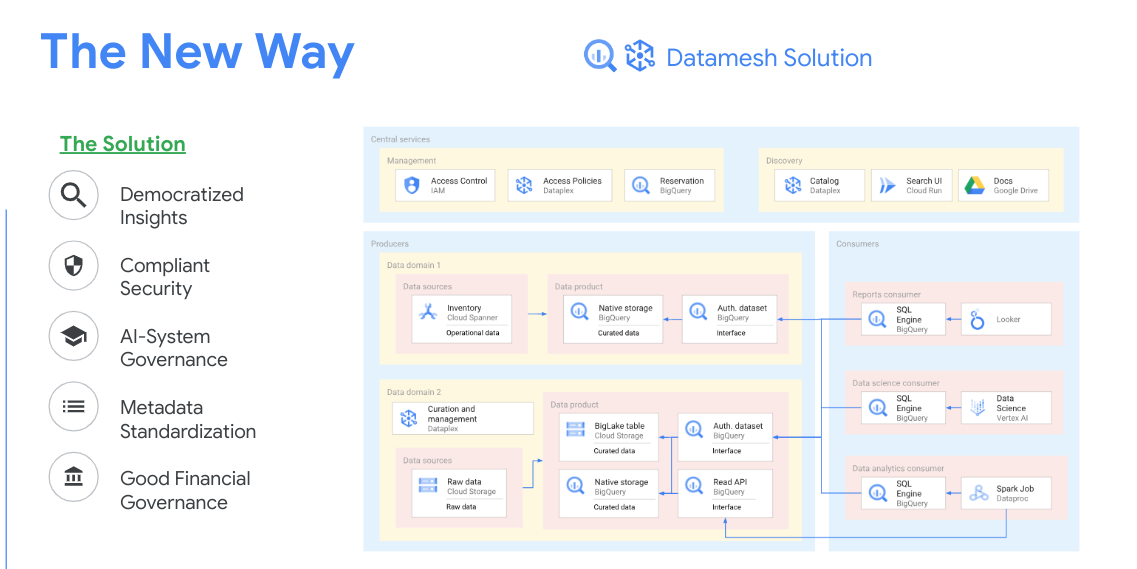
What is Datamesh?
The old way of
data management…

Legacy data management practices often rely on centralized, monolithic architectures, where data is governed and accessed from various disconnected systems. This approach creates bottlenecks, limits data discoverability, and hinders scalability, leading to slow decision-making and increased operational costs. In contrast, a data mesh promotes a decentralized, domain-oriented structure, where each team treats its data as a product, abstracted away from the underlying infrastructure. The primary focus of this approach is improvement of data cataloging, pipelines, quality, and accessibility while maintaining compliance through data lineage, data profiling, and auditing capabilities. This approach ensures value-driven cost controls and accountability.
0. Getting Started (Cloud)
To get started, you need a cloud provider or infrastructure service that aligns with your data needs and budget. For data warehousing, services like Google BigQuery, Amazon Redshift, or Snowflake provide scalable solutions optimized for analytics. For data lakes, consider AWS Lake Formation, Azure Data Lake, or Google Cloud Storage for flexible, large-scale data storage.
Organizations can then leverage these open source technologies to build a Datamesh framework:
OpenLineage and Apache Airflow can be leveraged for lineage.
Apache Ranger is often used for decentralized access control.
Dbt (data build tool) is useful for transforming and testing data pipelines.
Great Expectations for automated data quality checks empower teams to maintain high data standards autonomously.
Alternatively, pre-built SaaS solutions also exist, such as Collibra, Informatica, and Alation; each of these vendors provide a data cataloging, data quality, data lineage, and auditing capabilities. Google Cloud also launched it’s data governance platform, which I helped design, called Dataplex. These services can be further enhanced through extensive metadata collection and data-loss-prevention services.
1. Data Loss Prevention (DLP)
Traditional data loss prevention often relies on centralized security frameworks, creating performance challenges as data scales. In a data mesh, DLP can be embedded in each data domain to allow domain teams to define security controls specific to their data types, using tools like Apache Ranger for managing access policies and Sentry for monitoring data access patterns. Domain-level DLP frameworks, such as those enabled by HashiCorp Vault for secrets management, ensure sensitive data remains protected near its source, limiting exposure risks and aligning with compliance requirements.
Impact on AI: Embedding DLP at the domain level allows AI models to incorporate sensitive information within secure environments, opening the potential for more robust models without compromising privacy or regulatory compliance.
2. Data Annotations and Metadata Management
Annotations enrich datasets with context, facilitating their effective use across teams. Centralized legacy annotation frameworks often limit data discoverability. In a data mesh, annotations and metadata management can be handled by each domain using open-source tools like Amundsen or DataHub for metadata tracking and cataloging. These tools allow teams to document data origin, transformations, and context in a shared repository, which can also be integrated with Apache Atlas for enterprise-grade metadata and governance capabilities.
Impact on AI: Rich metadata and annotations enable data scientists to quickly understand data context, crucial for training high-accuracy, domain-specific models, and reducing time spent on data exploration and preparation.
3. Data Classification
Data classification is crucial for organizing, securing, and managing data at scale. In a legacy environment, classification processes are often centralized, leading to gaps as data changes over time. With a data mesh, classification can be standardized yet decentralized, enabling domain teams to apply tags and labels using tools like Apache Atlas or OpenMetadata. These tools allow classification to be uniformly applied and updated within each domain, helping to ensure that sensitive data remains properly labeled and governed across the organization.
Impact on AI: Uniform data classification across domains supports AI models by making it easier to locate, structure, and understand datasets. Consistent classification also supports automated cataloging and recommendation engines, enabling data scientists to discover relevant datasets across the organization.
4. Data Profiling
Data profiling—analyzing datasets to understand their content, structure, and quality—is essential to effective data management. Legacy data profiling often occurs infrequently, providing only a limited view of data quality. In a data mesh, profiling is a domain-specific, ongoing process. Each domain team can utilize tools like Great Expectations or Deequ (an open-source library for data quality) to continuously profile and validate data. These tools help identify data quality issues early, like outliers and inconsistencies, and enable more accurate, reliable datasets.
Impact on AI: Continuous data profiling improves AI model performance by ensuring data consistency. Ongoing profiling detects data drift or distribution changes, alerting teams to quality issues that could impact model accuracy, allowing for proactive adjustments.
5. Data Quality Management
Data quality management is fundamental in a data mesh, where data is distributed across domain teams. Legacy quality practices often rely on centralized checks, leading to inefficiencies in maintaining standards across diverse datasets. In a data mesh, tools like Great Expectations or dbt support automated testing, validation, and feedback loops within each domain. Each team can set and monitor quality thresholds tailored to their data, maintaining high standards that align with organizational objectives. With Great Expectations, domains can automate validation steps and continuous monitoring.
Impact on AI: High data quality improves AI model outputs, reducing the time spent on data cleaning and ensuring AI models are trained on reliable, consistent data. Decentralized quality management allows faster model training cycles and builds trust in AI-driven insights.